Список вебинаров
Введение (бесплатный)
Продолжительность: 2-2.5 часа
1
О серии вебинаров. Нагрузка, характеристики нагрузки. Запросы, задержка, конкурентность, отказы. Характеристики нагрузки. Экономика высоконагруженной системы. Ресурсы и их ограниченность. Успех проекта как его способность масштабироваться. Надежность. Внедрение изменений.
Как устроены вебинары, обзор всех вебинаров, логика рассмотрения тем. Определение общих терминов - нагрузка и ее характеристики, почему понятие “высокая нагрузка” относительна. Почему так важно масштабирование и когда оно не нужно, вертикальное и горизонтальное масштабирование. Надежность системы, примеры, определение доступности. Цена отказа, способы обеспечение надежности, независимость отказов. Внедрение изменений в масштабах проекта (компании), подготовка, ожидаемый результат, трудные ситуации. Модель веб-проекта, узкие места, сложность масштабирования и обеспечения отказоустойчивости.
В рамках этого вебинара вы узнаете:
- из чего состоит курс вебинаров? почему выбраны именно эти темы?
- что такое нагрузка, как ее измерять, что такое высокая нагрузка?
- как обеспечить надежность (доступность)?
Данные часть 1. От основ хранения до РСУБД
Продолжительность: 4 часа
2
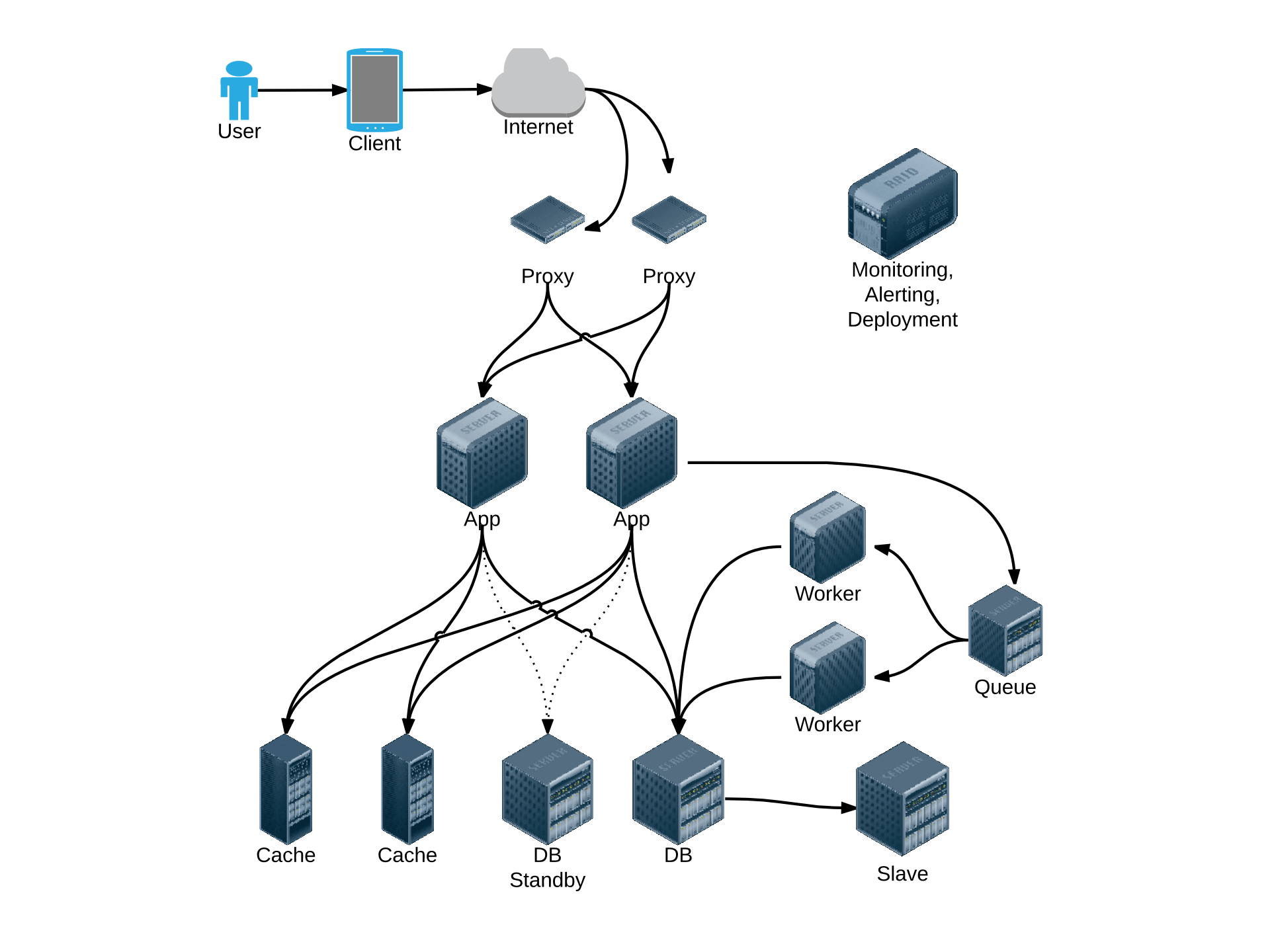
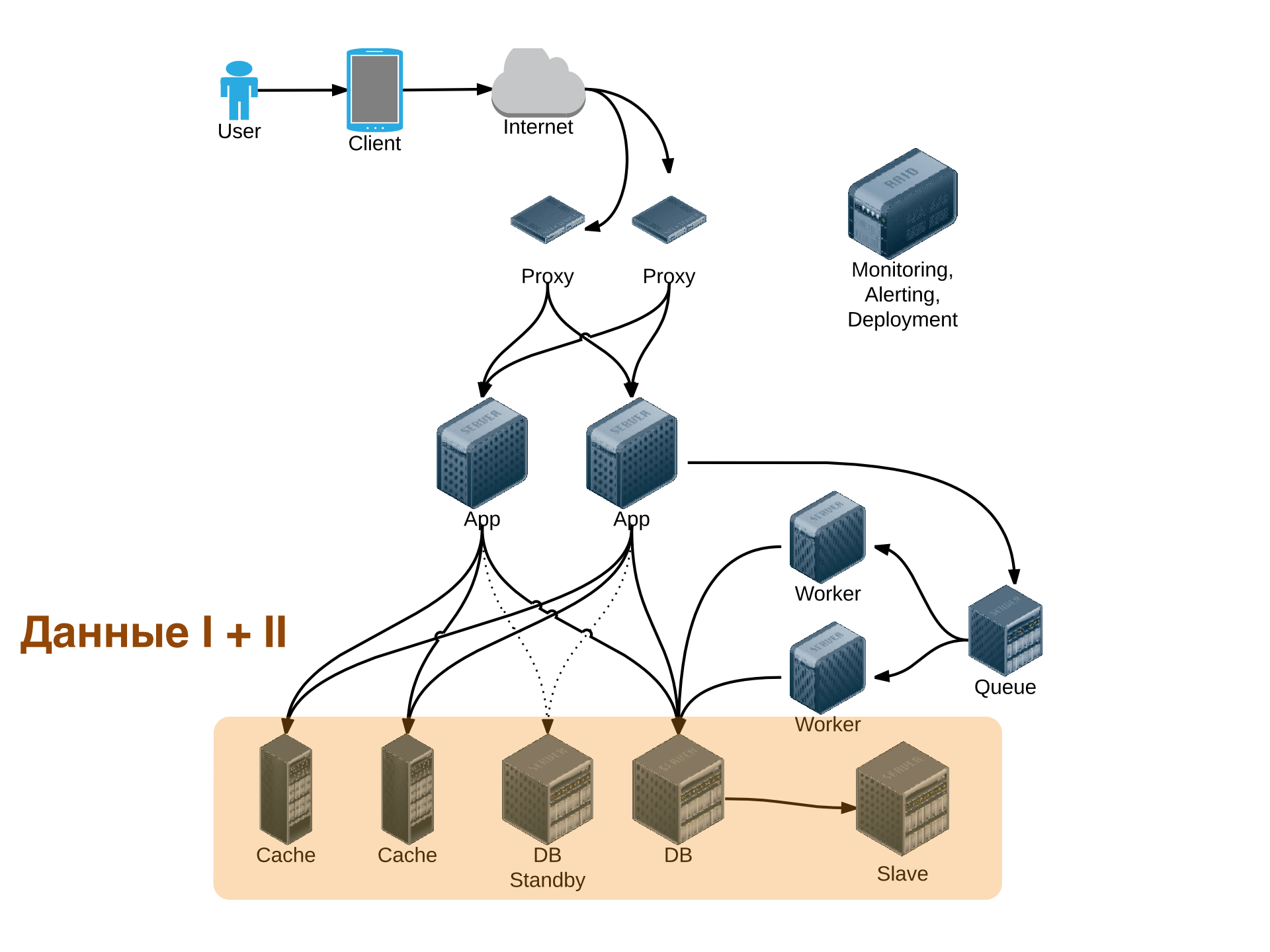
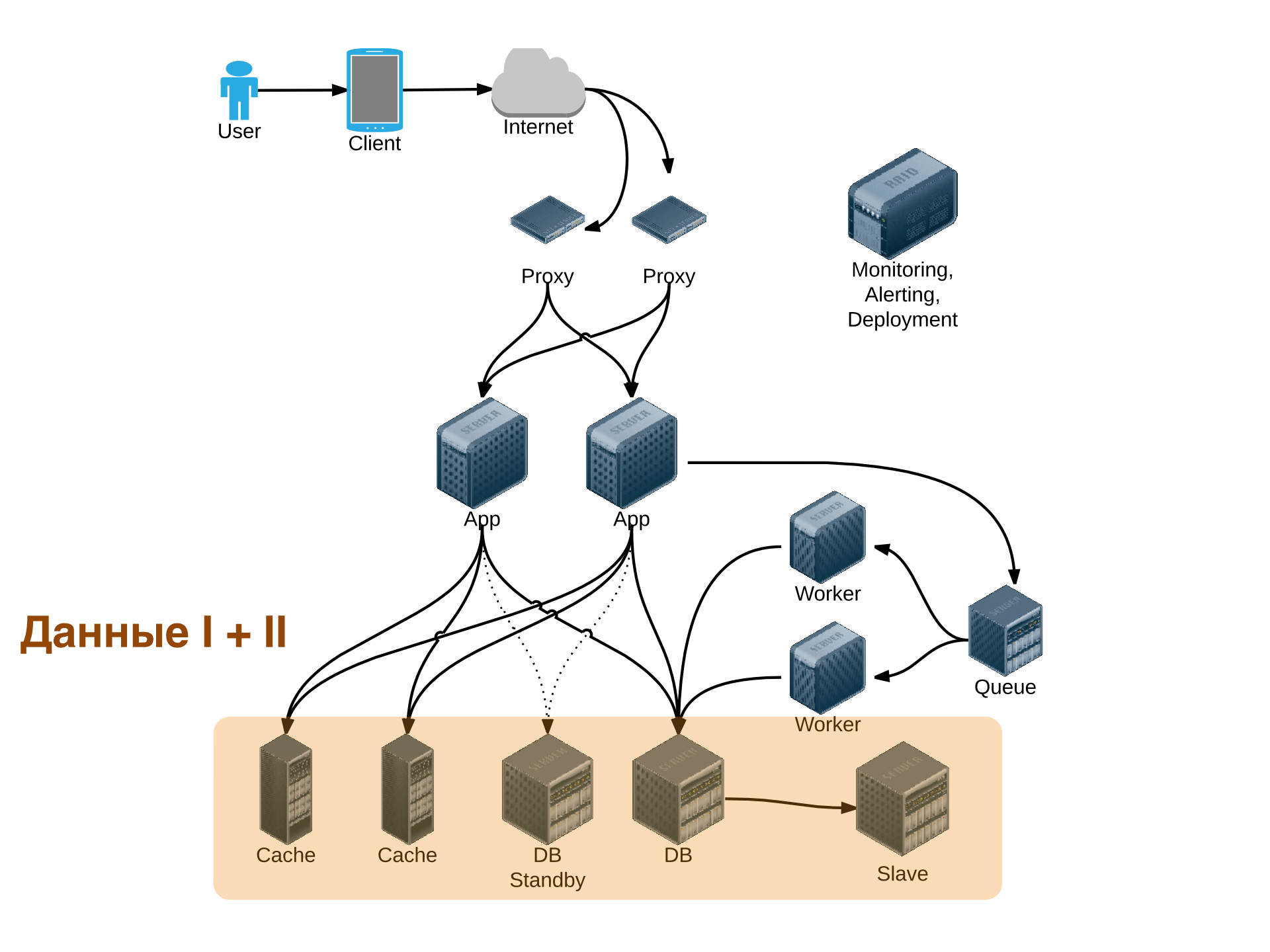
Базовые принципы хранения данных. Хранение на диске и в памяти. ACID. Реляционные БД. Проектирование схемы реальной БД в различных моделях данных. Индексы, денормализация, использование разных типов хранилищ для разных данных. Партиционирование. Репликация. Полнотекстовый поиск.
Хранение данных - ключевой вопрос с точки зрения как масштабирования, так и отказоустойчивости проекта и, чаще всего, самый сложный. Мы начнем рассмотрение темы с вопросов хранения данных на одной машине: как можно хранить данные, как это делать эффективно, можно ли хранить данные в памяти. Чем отличается хранение на SSD и HDD? Самым популярным и все еще самым часто используемым вариантом хранения являются реляционные базы данных. На примере MySQL, PostgreSQL мы рассмотрим все то, что можно “выжать” из одиночного сервера баз данных. Как хранятся данные в РСУБД. Что такое MVCC и что это означает с точки зрения производительности и конкурентного доступа. Как устроены индексы и какие индексы могут быть полезны. Вычисление плана и результатов запросов. Почему классический подход к проектированию базы данных неприменим при высоких нагрузках. Практические трюки с базой данных ради увеличения производительности.
Как должно быть устроено обращение к базе данных, выжимаем максимум из драйвера БД. Мы рассмотрим различные варианты репликации данных и обсудим, что они могут дать с точки зрения производительности и отказоустойчивости. Полнотекстовый поиск - теория и практика, в каких задачах полнотекстовый поиск мог бы пригодиться.
В рамках этого вебинара вы узнаете:
- хранение на диске: можно ли сделать еще быстрее? какой способ хранения выбрать?
- когда применимо хранение в памяти? какие архитектурные преимущества мы можем получить?
- являются ли сегодня реляционные СУБД возможным решением для хранения данных в высоконагруженном проекте?
- как выжать из базы данных максимум? как обеспечить отказоустойчивость?
- как устроен полнотекстовый поиск, где границы его применимости?
Логическим продолжением этого вебинара будет вебинар “Данные часть 2”.
Данные часть 2. Шардинг, key-value и распределенные хранилища
Продолжительность: 4 часа
3
Масштабирование: шардинг в реляционных и key-value хранилищах. Key-value хранилища. CAP-теорема. Распределенные хранилища. Консистентность. Кешированные данных: инвалидация кеша, тегирование кешей.
Данный вебинар является логическим продолжением вебинара “Данные часть 1”.
Масштабирование хранилища данных, обеспечение отказоустойчивости - это то, с чем раньше всего придется столкнуться веб-проекту под растущей нагрузкой и требованиями надежности.
Шардинг: просто о сложном, выбор ключа шардирования. Когда внедрять шардинг: заранее или когда “придет время”? Проектирование с учетом шардинга. Как избежать решардинга и как его сделать, если все-таки необходимо. Особенности шардинга в реляционных базах данных. Шардинг и отказоустойчивость. Одиночные key-value хранилища: memcached, Redis, корректная реализация счетчиков, блокировок и тому подобных распределенных структур данных. MongoDB как пример распределенного key-value хранилища. CAP-теорема: что невозможно реализовать и какие классы систем существуют. Multi-master решения и их область применимости. AP-распределенные хранилища на примере Cassandra и Riak. Виды консистентности и их влияние практическую разрабтку программного обеспечения. Как обеспечивается консистентность.
Кеширование как способ уменьшения нагрузки на хранилище данных и уменьшения времени отклика. Как организовать кеширование? Основные проблемы при кешировании и их решения.
В рамках этого вебинара вы узнаете:
- как осуществлять горизонтальные масштабирование данных? как связана отказоустойчивость и горизонтальное масштабирование?
- как правильно выбрать ключ шардирования и почему этот выбор может оказаться критическим?
- каким образом распределенные системы хранения данных достигают своих характеристик?
- как организовать корректное кеширование данных, как избежать проблем консистентности?
Приложение
Продолжительность: 4 часа
4
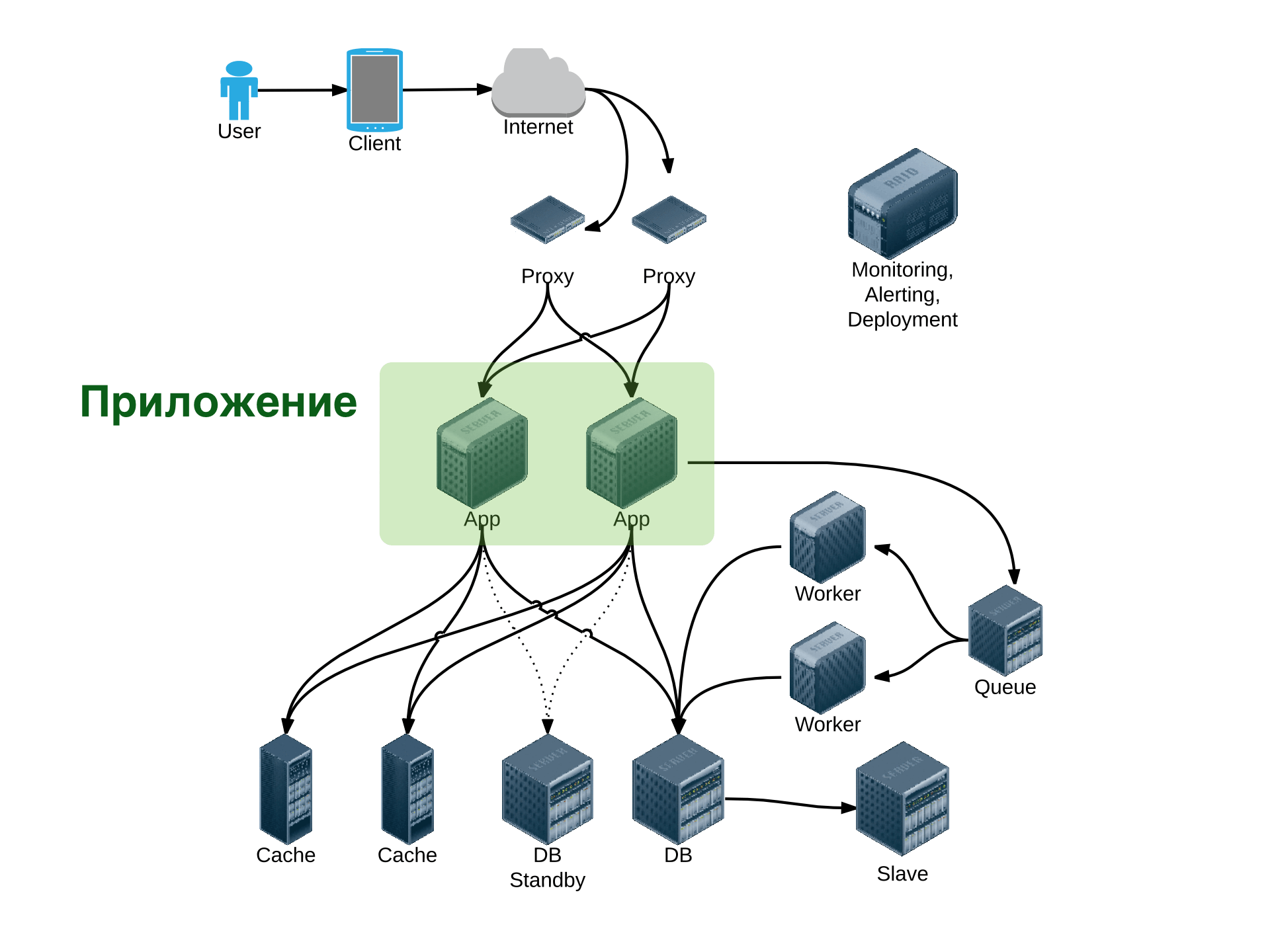
Структура серверного и клиентского приложения, анализ узких и проблемных мест. Сетевой ввод-вывод: синхронный, асинхронный. Реактор, обслуживание большого числа соединений (C10K, C100K). Многозадачность: процессы, нити, кооперативная многозадачность, комбинации. Краткий обзор фреймворков и языков программирования: Ruby, Python, Go, Java, C#, Erlang, JavaScript. Безопасность. Типичные уязвимости. Пользователи и пароли. CSRF.
Мы будем обсуждать внутренне устройство одного из ключевых компонентов веб-системы: backendа. Выбор внутренней архитектуры backendа - способа сетевого ввода-вывода, вида многозадачности - определяет его производительность. Мы обсудим то, каким образом это может быть реализовано, какое влияние оказывает на производительность. Рассмотрим комбинированные варианты, а также то, какие виды многозадачности и сетевого ввода-вывода используют популярные базы данных, веб-сервера и т.п. На примере различных языков программирования и фреймворков будут проанализированы различные варианты реализации многозадачности, их влияние на код проекта и его сопровождаемость в дальнейшем.
Вопросы безопасности невозможно обойти стороной - хоть они напрямую не влияют на производительность или надежность системы, их необходимо учитывать при разработке качественного продукта. Мы рассмотрим основные проблемы безопасности и способы их решения.
В рамках этого вебинара вы узнаете:
- как увеличить производительность backendа? чем она ограничена?
- какой язык программирования/фреймворк выбрать?
- какие предпринять шаги для обеспечения безопасноти?
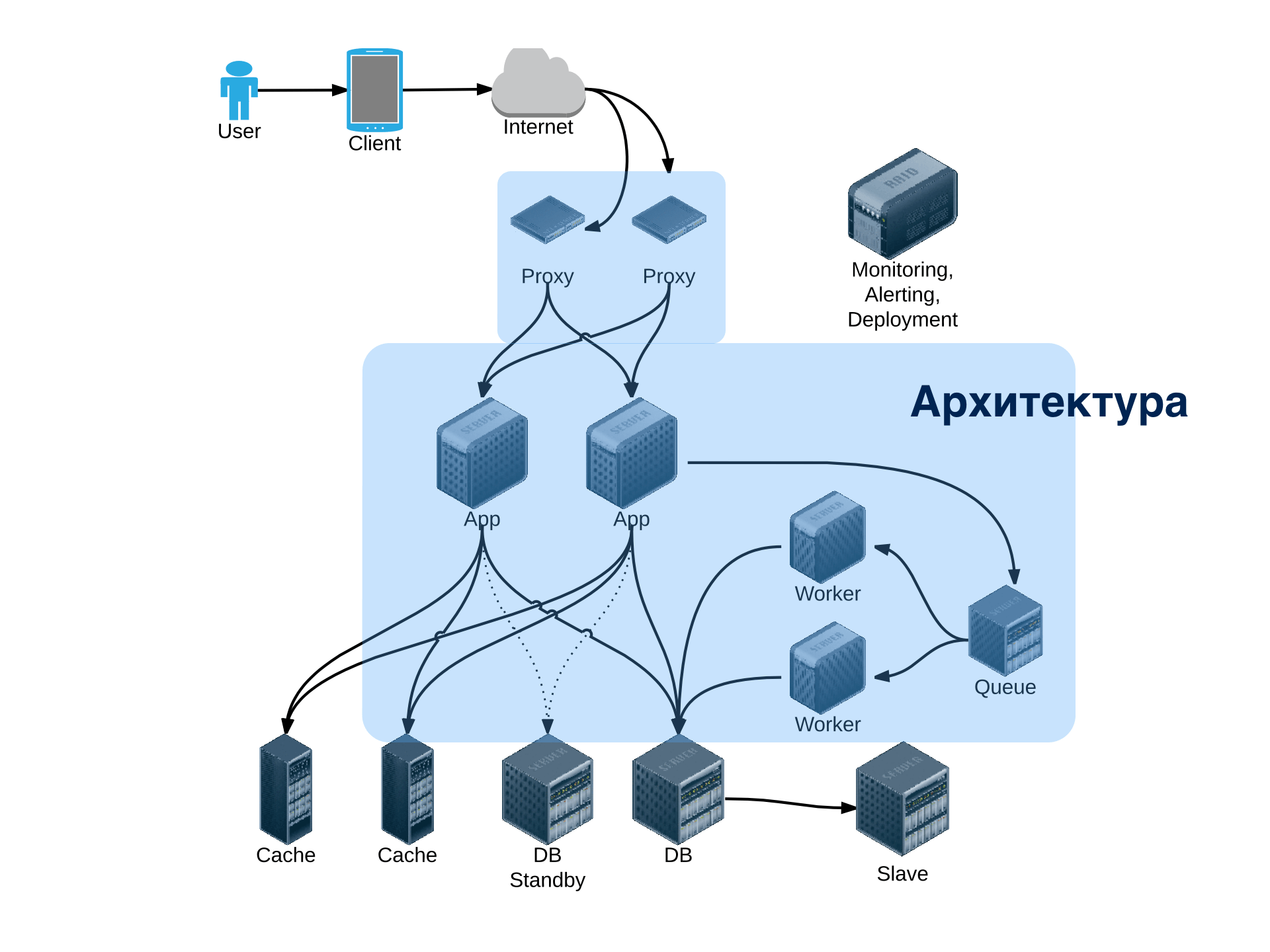
Архитектура веб-систем
Продолжительность: 4 часа
5
Архитектура системы: монолитная, сервис-ориентированная (SOA). Непосредственный вызов (RPC), очереди, персистентные очереди, очереди фоновых задач. Шины, широковещательные каналы. Примеры и разбор реальных архитектур веб-приложений.
Мы посмотрим на архитектуру с высоты “птичьего полета” и рассмотрим вопросы взаимодействия частей системы. Выбор между монолитным и сервис-ориентированным подходом. Переход от монолитной к сервис-ориентированной архитектуре. Проектирование взаимодействия компонентов, выбор протоколов, видов связи. Способы реализации типичных паттернов взаимодействия: удаленный вызов, очередь, publish-subscribe, worker, шина. AMQP-серверы и ZeroMQ. Высокопроизводительные сервисы очередей и простые решения для очереди задач. Надежность доставки сообщений в очереди.
Мы рассмотрим примеры реальных архитектур веб-приложений, оценим их достоинства и недостатки, посмотрим на трансформацию архитектуры при изменении нагрузки. Как избежать “узких мест” еще на этапе проектирования, как заложить потенциал будущего масштабирования. Архитектура системы как отражение организационной структуры команд разработки.
В рамках этого вебинара вы узнаете:
- какую архитектуру проекта лучше выбрать?
- как должна изменяться архитектура по мере роста проекта?
- какой вариант взаимодействия подсистем лучше использовать?
- могут ли очереди решить все проблемы взаимодействия?
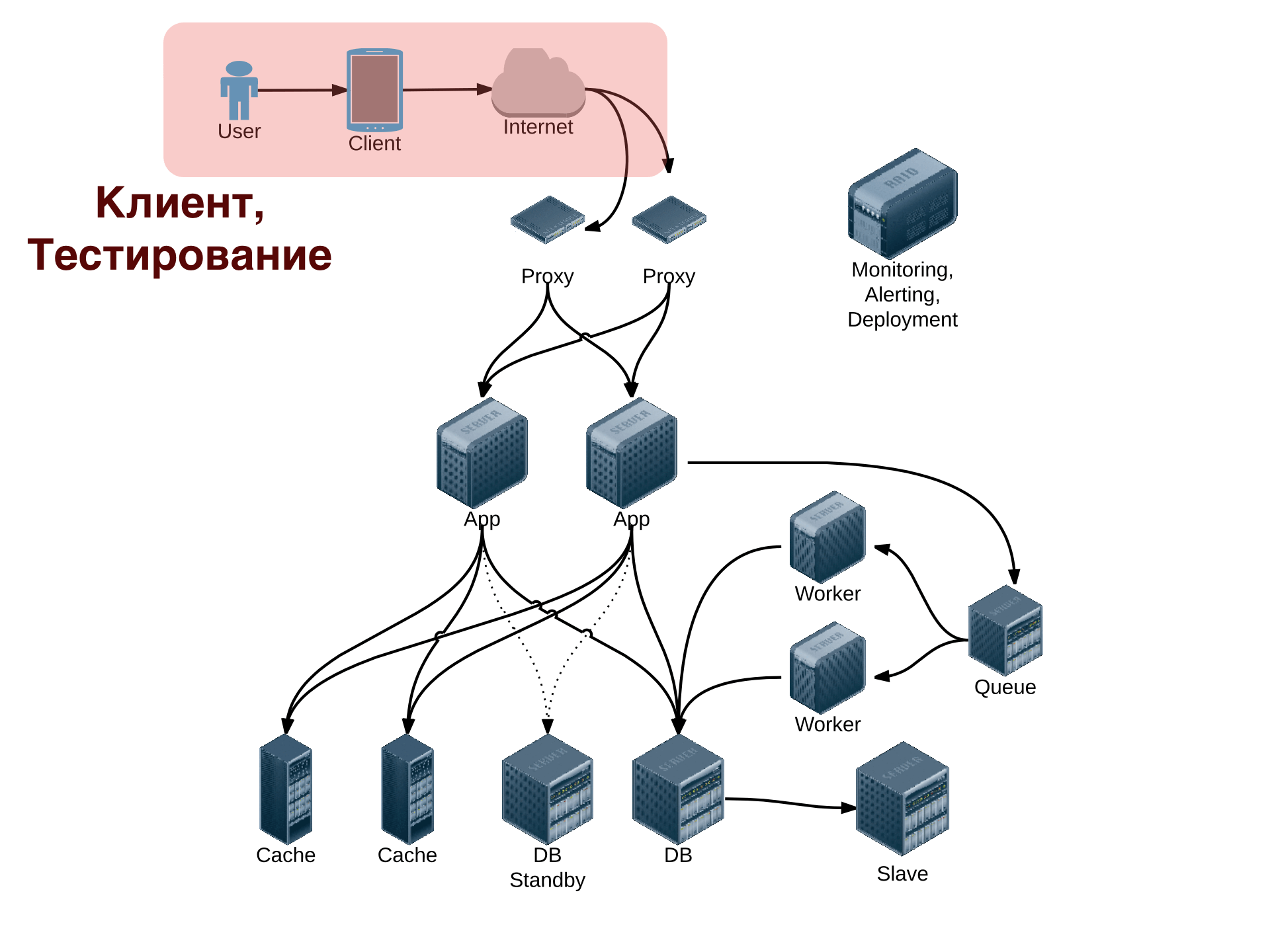
Взаимодействие с клиентским приложением. Тестирование
Продолжительность: 4 часа
6
Синхронизация данных, работа в offline, информирование пользователя. Сетевое взаимодействие с сервером. Ошибки API. Клиент как веб-сервис. Алгоритмы повтора запроса. Нагрузочное и системное тестирование. Почему unit-тестирование бесполезно. Непрерывное тестирование, постоянное выкатывание.
Продукт сегодня редко можно представить без взаимодействия клиентского приложения и серверной части. Как эффективно организовать это взаимодействие? Какие ограничения накладывает сеть, проблемы неопределенности, условия повтора запроса. Как должно быть спроектировано API сервиса, чтобы взаимодействие клиент-сервер было более эффективным? Синхронизация данных между клиентом и сервером, проблема конфликтов. Мгновенный отклик в приложении, синхронизация кеша клиента, применение отложенных действий. Информирование пользователя об ошибочных ситуациях.
Как организовать тестирование веб-системы. Идеальное тестирование и попытки к нему приблизиться, автоматизация тестирования. Почему вы можете удалить почти все unit-тесты, и какая от этого будет польза. Системное тестирование, его преимущества. Тестирование в боевом окружении, нагрузочное тестирование, использование нагрузочного тестирования для планирования ресурсов. Постоянное выкатывание как способ минимизации числа отказов.
В рамках этого вебинара вы узнаете:
- как выстроить таймауты при взаимодействии клиент - сервер?
- как организовать работу клиента в режиме offline?
- как сделать тестирование эффективным и избавиться от бессмысленных тестов?
- как провести нагрузочное тестирование и делать это регулярно?
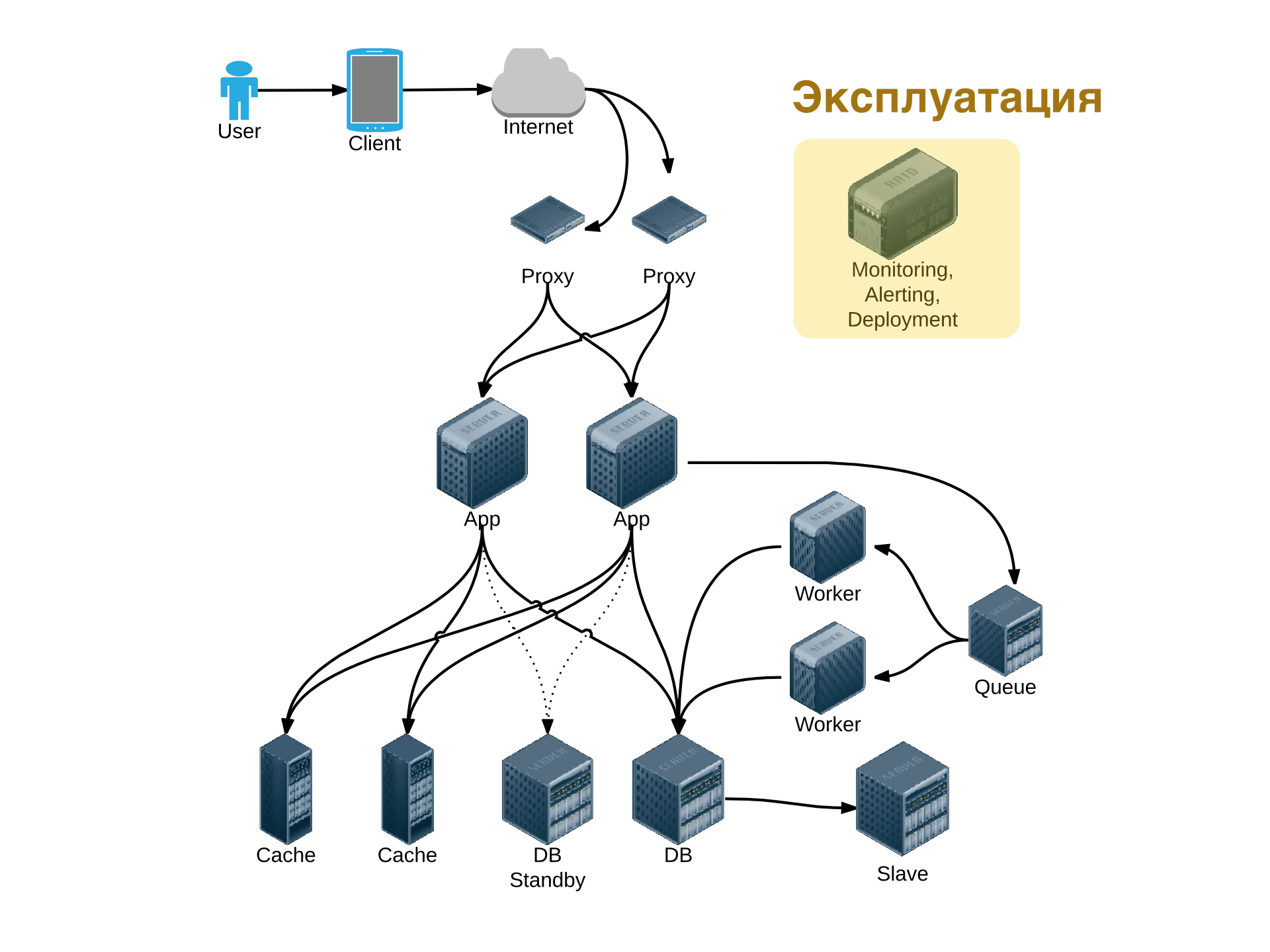
Отказоустойчивость, мониторинг и выкатывание
Продолжительность: 4 часа
7
Оценка нагрузки и планирование ресурсов. Резервное копирование, репликация. Master-Slave. Hot-Spare. Несколько дата-центров, схемы Active-Failover, Master-Slave, Active-Active. Обеспечение консистентности. Протоколы голосования. Выбор между “облаком” и железом. Выкатывание проекта, управление конфигурацией. Логирование. Мониторинг.
После того как разработка и тестирование завершено, настало время выложить проект в боевое окружение и поддерживать его работоспособность. Мы начнем с оценки нагрузки и планирования ресурсов на простом примере. Затем мы поговорим об обеспечении отказоустойчивости и надежности - начиная от резервного копирования и заканчивая паттернами дублирования компонентов. Переход к работе проекта из нескольких дата-центров: в активном и активно-пассивном режимах, особенности работы в нескольких дата-центрах и обеспечения консистентности. Конфигурация системы, протоколы голосования, механизмы обнаружения сервисов, выявления сбоев, переключения конфигурации. Автоматическое управление конфигурацией, подходы и решаемые проблемы. Автоматизация выкатывания проекта. Централизованный сбор логов, мониторинг, сбор метрик, хранение, визуалзизация, триггеры.
В рамках этого вебинара вы узнаете:
- как оценивать необходимые ресурсы? как оценивать потребность в ресурсах при масштабировании?
- как обеспечить отказоустойчивость?
- как переключить запросы на другие копии ресурса в случае отказа?
- как компоненты системы могут “обнаруживать друг друга”?
- как автоматизировать управление конфигурацией и выкатывание проекта?